The Bayesian Dirichlet (BD) scoring function is defined as follows.

Click this link to see what each of these terms mean.
For a weekend project, I created a Java and JavaScript API for computing the BD scoring function. The project is open-source with Apache License v2.0. You may download the project from GitHub at https://github.com/vangj/multdir-core.
Let’s see how we may quickly use these APIs to compute the score of a Bayesian Belief Network (BBN). In [Cooper92], a set of data with three variables (X1, X2, X3) was given as follows.
| X1 |
X2 |
X3 |
| p |
a |
a |
| p |
p |
p |
| a |
a |
p |
| p |
p |
p |
| a |
a |
a |
| a |
p |
p |
| p |
p |
p |
| a |
a |
a |
| p |
p |
p |
| a |
a |
a |
There was also 3 Bayesian network structures (BS) to represent the relationships of the variables as well. Those 3 BS were reported as follows.
- BS1: X1 → X2 → X3
- BS2: X2 ← X1 → X3
- BS3: X1 ← X2 ← X3
In Java, we can use the API to quickly estimate the scores of BS1, BS2, and BS3 as follows.
double bs1 = (new BayesianDirchletBuilder())
.addKutato(5, 5) //X1
.addKutato(1, 4) //X2
.addKutato(4, 1)
.addKutato(0, 5) //X3
.addKutato(4, 1)
.build()
.get();
double bs2 = (new BayesianDirchletBuilder())
.addKutato(5, 5) //X1
.addKutato(1, 4) //X2
.addKutato(4, 1)
.addKutato(2, 3) //X3
.addKutato(4, 1)
.build()
.get();
double bs3 = (new BayesianDirchletBuilder())
.addKutato(1, 4) //X1
.addKutato(4, 1)
.addKutato(0, 4) //X2
.addKutato(5, 1)
.addKutato(6, 4) //X3
.build()
.get();
Likewise, in JavaScript, we can also quickly estimate the scores of these BBNs as follows.
var bs1 = (new BayesianDirichletBuilder())
.addKutato([5,5])
.addKutato([1,4])
.addKutato([4,1])
.addKutato([0,5])
.addKutato([4,1])
.build()
.get();
var bs2 = (new BayesianDirichletBuilder())
.addKutato([5,5])
.addKutato([1,4])
.addKutato([4,1])
.addKutato([2,3])
.addKutato([4,1])
.build()
.get();
var bs3 = (new BayesianDirichletBuilder())
.addKutato([1,4])
.addKutato([4,1])
.addKutato([0,4])
.addKutato([5,1])
.addKutato([6,4])
.build()
.get();
Notice how in both APIs, you only add the counts? Easy.
Also, a working demo of using the JavaScript API to compute the BBN scores is in the repository for this project. Here’s a screenshot. Note that the scores are in log-space. Computing the score using factorials is not practical. In log-space, the lower the score associated with a BBN, the better the BBN.

As always, enjoy and cheers! Sib ntsib dua nawb mog!
References
- [Cooper92] G.F. Cooper and E. Herskovits. A Bayesian method for the induction of probabilistic networks from data. Machine Learning, 9, 309–347 (1992).


 is a set of discrete random variables
is a set of discrete random variables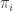 is the set of parents of
is the set of parents of  and
and 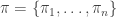
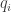 is the number of unique instantiations (configurations) of
is the number of unique instantiations (configurations) of  is the number of values for
is the number of values for 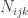 is the number of times (frequency of when)
is the number of times (frequency of when) 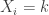 and
and 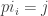 , and
, and 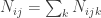
 is the hyperparameter for when
is the hyperparameter for when 
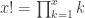 is the factorial function
is the factorial function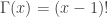 is the gamma function
is the gamma function is the BBN structure
is the BBN structure is the data
is the data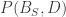 is the joint probability of the BBN structure and data
is the joint probability of the BBN structure and data